Automated Transparent Development


Every game developer has a dilemma -- you need to make a game (development), and you need to tell people about it (marketing) so they'll get it when it comes out. The more you do one, the more you neglect the other. If you just keep your head down and work,everyone will think your project is abandoned, but if all you do is talk about how great it is, you won't ever get anything done, and most of us have trouble finding the perfect balance.
I like to focus on work. So being a programmer, I figured maybe I can get these computers I'm always using to automate some of our marketing.
It's what I call Automated, Transparent Development, or "ATD", and it consists of four things:
- Public to-do list
- Automated progress tracker
- Nightly build server
- In-game crash logger + remote server listener
Of course, we have all the other usual community features, such as our forum, our newsletter, and all those fancy little social media buttons at the top of this post, but the key difference is the traditional stuff constantly demands input, whereas ATD can chug along all by itself.
1. Public to-do list.
The number one thing your fans want to know: "Is the Game Dead?"
The public to-do list is a great solution, it's pretty easy to set up, and doesn't require you to expose any of your actual game code, just your current progress.
How I Did it:
- Create a Github repo just for issue tracking (source code is stored elsewhere).
- Link said repo to a nicer front-end, namely Waffle.io
- Create and close issues as we work. Use this for tracking everything.
The Github repo looks like this:
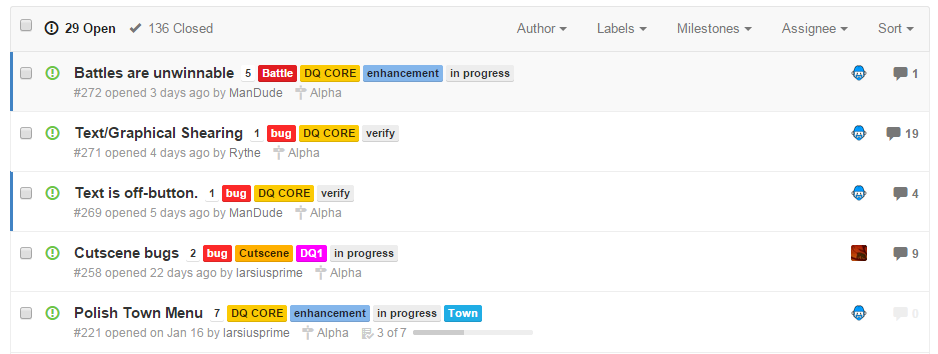
I prefer Waffle.io because it's easier to interact with, and you can combine issues from multiple repos, so I can also keep track of the open source projects I created for Defender's Quest Development (such as flixel-ui) that also need work:
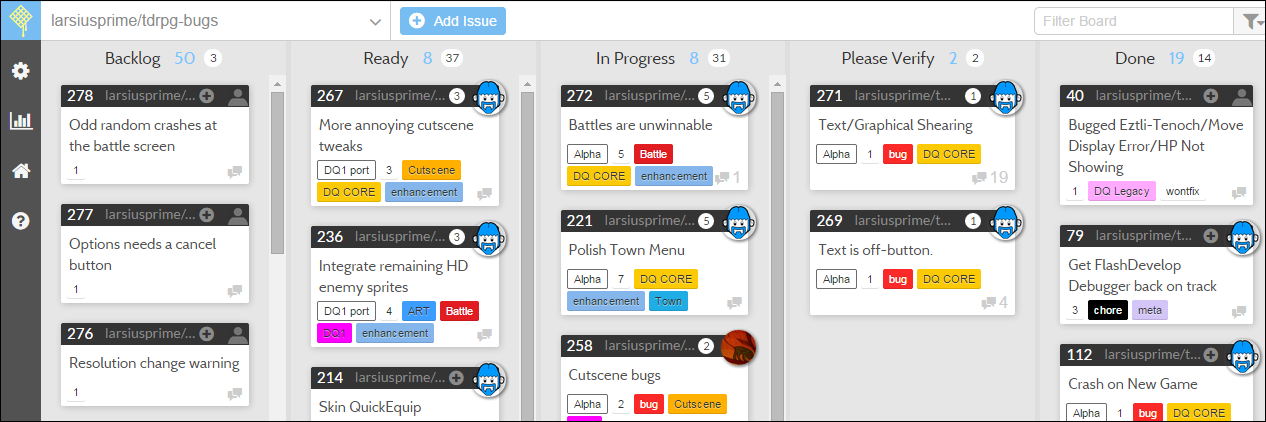
Curious users can browse the issues and see what is getting done. This way even if you're doing just a commit or two a week, fans who keep asking "Is the game still under development?" don't have to wait for a big "official" blog or forum post. Another fan will probably check in and quickly verify, "latest ping was yesterday, pulse seems steady!"
This public to-do list also doubles as a natural place for testers and players to report bugs!
Downsides: now your fans are all up in your grill, you should be prepared for that :) Also if you have any super secret sauce you can't reveal in your public issue tracker, that can be awkward as now you have to track that somewhere else.
2. Automated Progress Tracker
You can see the automated progress tracker in action here.
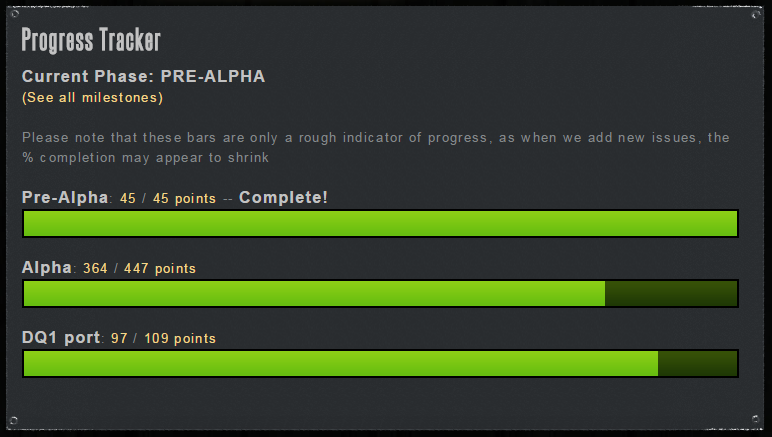
I wrote about it briefly before in this article. Back then it was just doing a simple client-side javascript query to the Github API, fetching the milestones, and displaying the number of open/total issues per milestone.
Since then I've tweaked it to work off of "points" instead. You see, sometimes I like to put lots of checkbox sub-tasks in each issue report and tick them off one by one. But I also sometimes have tiny issues that take 30 minutes to finish. The old system counted these the same.
Waffle.io has a method for assigning "points" to issues, but it currently doesn't have an API for fetching these, and Github has no concept of points. So as a work-around I just created a bunch of numeric labels to stand in for points.
However, that required a serious change in my logic as Github's API doesn't let you easily fetch that information in one call. Instead, my friend and colleague Adam Perry wrote a script to calculate this stuff. It consists of:
- A php file that runs on your server and outputs a json file to the web directory
- The JSON file outputted by step 1
- Some front-end javascript to read the JSON and draw the progress bars
You can find all three of those in this Github gist.
You'll also need some simple images to draw your progress bars, I just used a 1x20 green gradient for the bar and a 1x20 solid black image for the background.
This is a big step up as it makes everything nice and simple for users. The last step is to set up a cron job to run the script.
On your server run:
crontab -e
Which will open up a text file where you store instructions for cron.
Then you add this line:
00 03 * * * php -e /path/to/dqbugs.php
That will cause your server to run that script every day at 3:00 AM, generating a new JSON file. Now your progress bars will update once per day.
3. Nightly Build Server
With the original Defender's Quest, I did every build by hand. Not only was this a lot of work, it was error prone as I would forget certain steps. The end result was that it would take most of the day to do a "full deploy" of Mac/Windows/Linux builds to all the places they needed to go. Even though we're not at full release for DQ1HD / DQ2 just yet, we still need to provide fresh builds for testers and alpha backers.
Nightly builds are really important!
We use TeamCity for Defender's Quest HD's nightly mac, windows, and linux builds. Setting up my particular TeamCity solution was not free, but I'm definitely happy to pay for this setup as it saves me gobs of time.
Let's be honest -- without automation, we'd have monthly builds, at best. I'm just not that dilligent.
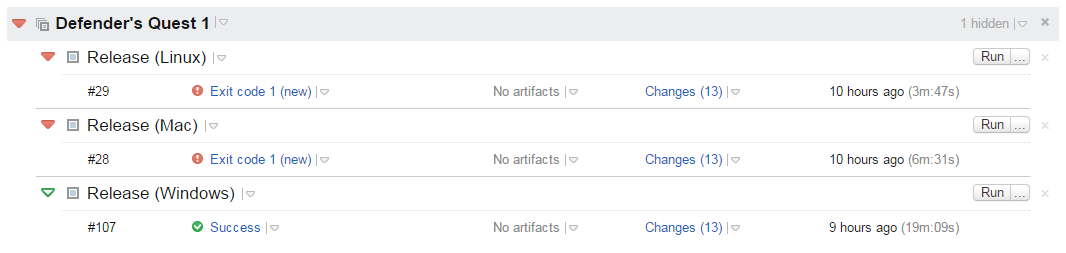
TeamCity shows which builds are currently working. In this example, Windows passed and Mac/Linux are failing.
The overview is simple:
Every day:
- The remote server fetches the latest source code from a list of repositories
- Server runs configuration script
- Server runs build script
- Server runs deploy script
- Files show up in our cloud folder ready for testers/alpha backers to grab
The details are more complicated, and since I had a friend set this up for me I can't give you an exact tutorial, but I'll give you the broad strokes.
-
The TeamCity instance is installed on a (linux) VPS that we control.
-
You need to set up a remote "agent" for each operating system you want to build for
a. Linux: use existing Linux VPS TeamCity is running on
b. Windows: use a Windows VPS at Hostwinds
c. Mac: use a Mac VPS at HostMyApple
d. Install TeamCity client on each of these agents and configure the main host server
(You can always use your own local mac/win/linux machines, but you might have to deal with crappy upload speeds) -
Install dependent boilerplate software on your agent machines.
In my case this is the basic Haxe toolkit (compiler, package manager, etc), but not any Haxe source code libraries. -
Set up your build configurations
I have three: Release(Mac), Release(Linux), Release(Windows). -
Set up version control sources
I track a lot of in-development open source libraries, but for my own sanity's sake, my nightly builds are based off of my own stable forks. That way someone can't break the build with a commit to a library I don't maintain and screw up my nightly builds. I just check in each morning, grab the latest source, make sure I'm building fine locally, then push to my forks. -
Set up build steps
a. Setup: install libraries from package manager and/or link to version control folders
b. Build: run the build command for the game.
c. Deploy: upload results to remote cloud drive.
4. Crash logger + remote server listener
Bugs are one thing, but crashes are another. Not only are crashes hard for users to report, they need detailed data to reproduce, and it's really annoying for both developer and tester to go through the "okay what operating system were you using, what was the last thing you did, etc."
A lot of that basic information can and should be supplied by the system itself. The tester should supply reproduction steps if they can, but the system knows exactly what graphics card they have, as well as the exact call stack before the crash occured.
So whenever Defender's Quest crashes, it brings up a screen like this:
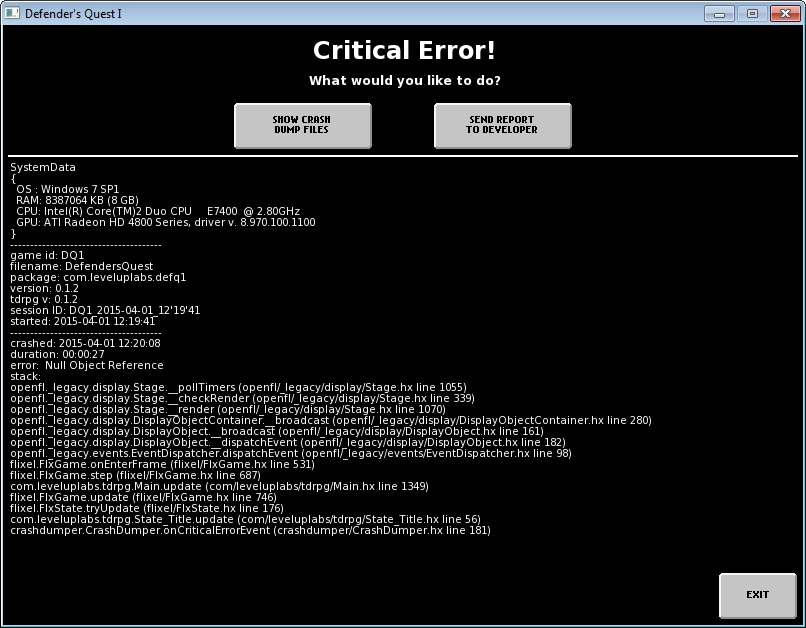
Clicking "show crashdump files" opens this folder:
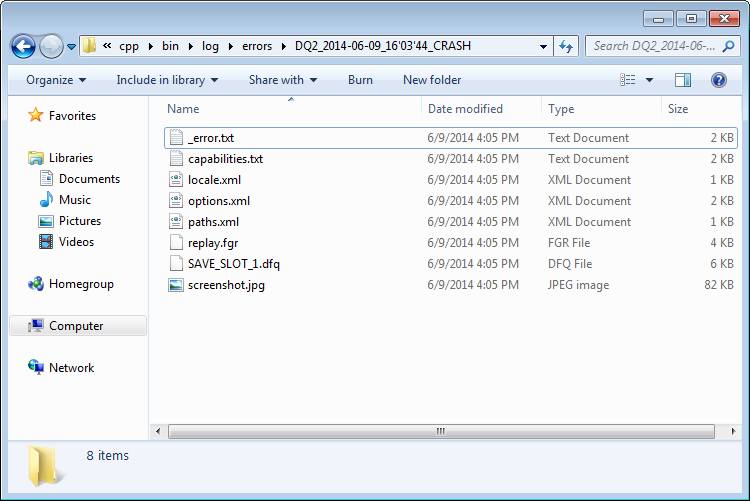
Which contains useful data like this:
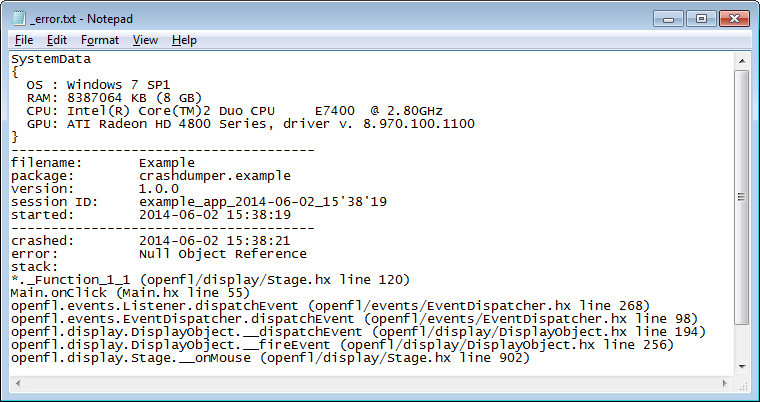
This is thanks to my handy-dandy, open source CrashDumper library. It only takes a few lines of code to insert into any OpenFL project, and it will give you detailed information:
- User's operating system, RAM, CPU, GPU, etc
- Game version, time & date of crash, etc
- Error message & call stack
- Other custom information
In Defender's Quest, I added custom extensions to take a screenshot right before the crash dump, and to also supply a stored snapshot of the game's beginning state when it was loaded - the save files at the time of launch, the options data, etc, and a complete replay record starting from when the game was loaded. All of this gets logged too.
Now, normally this just sits on the user's local machine. This is a big step up just by itself - you can ask your testers to submit crash dump files with a bug report.
However, you can configure CrashDumper to talk to a remote server too, and automatically send those reports straight to the developer! (And yes, we'll add notifications/user options about this before final release, and deactivating all such remote server sends in the GOG version entirely).
The crashdump browser (also written by Adam Perry) looks like this and is really easy to use:
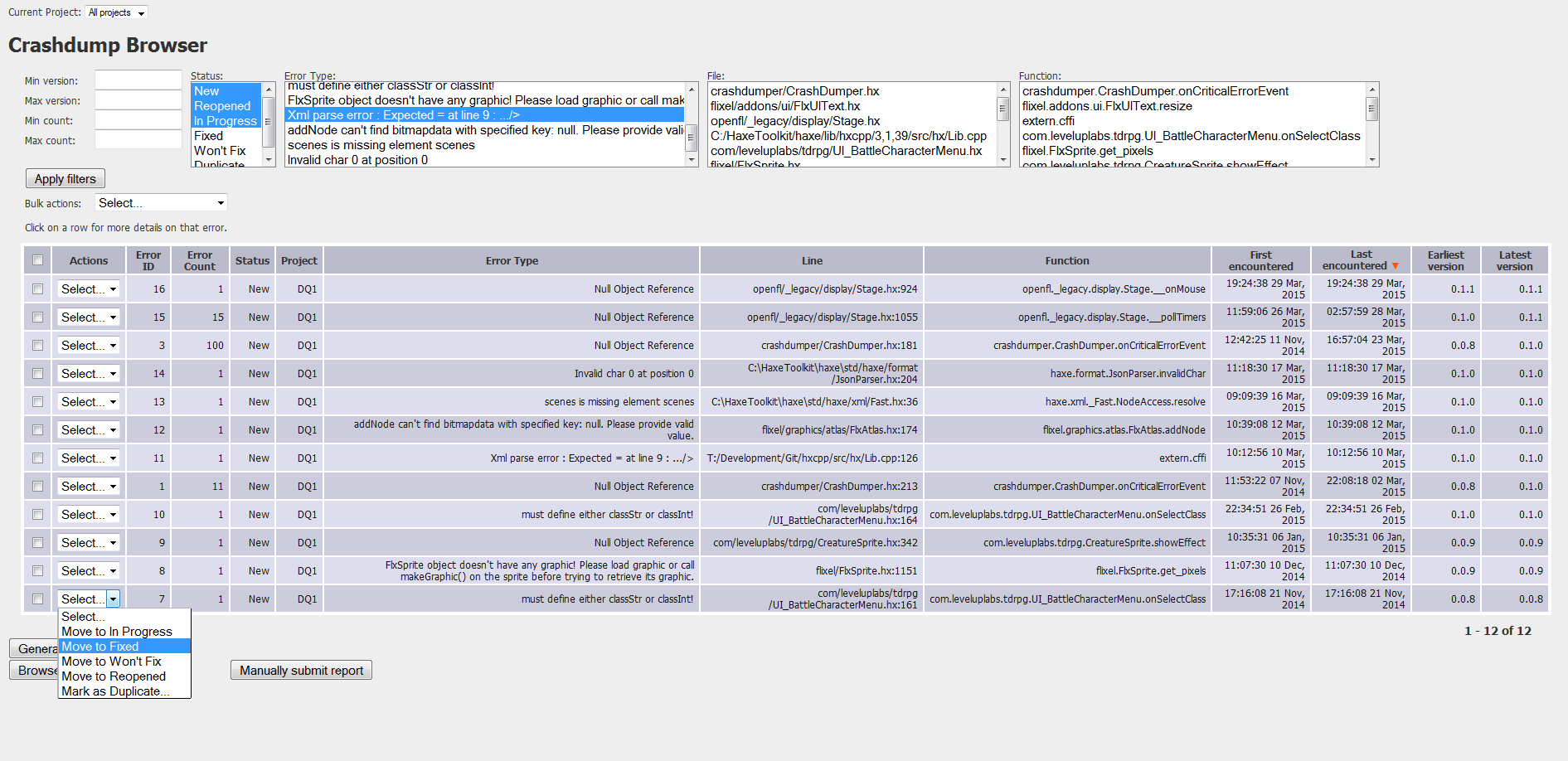
It's simple to install it on your local webserver and connect to your client, and gives you a nice frontend to get all your crashes from testers and players. When your game goes live, you can collect all SORTS of errors you didn't even know were happening and get to fixing them before official bug reports start trickling in.
Summing up
So those are four things we do to facilitate Automated Transparent Development. Lots of people want to be transparent with their communities, but I just don't have the energy for Twitch streaming, weekly video updates, and I live in the middle of nowhere so it's a major effort to make it to big events.
Sometimes I just want to code for three months straight, and if the users can follow along with me without me having to confirm I'm still alive, great!
Of course, automation is no substitute for solid human interaction and community engagement, but it sure as heck greases the wheels.